基于Flask框架的动态代理池系统
一、项目简介
如今是网络与信息时代,互联网成为了大量信息的载体,它的出现是人类科学技术的一次革命,这场革命使得人们获取信息更加便利,更加可信,更加低廉,更加有趣。但这其中的信息是碎片分散的,之间的关系也是纷繁复杂的,所以如何有效地提取并利用这些信息成为了一个巨大的挑战。搜索引擎,例如传统的通用搜索引擎,例如Yahoo和Google等,作为一个辅助人们检索信息的工具,运用爬虫技术,成为用户访问网络的入口和指南[1]。
爬虫技术以极快的速度、极大的规模对信息进行检索和存储,但有些时候网络管理员并不想网站的内容被爬虫所获取,或者不想因为爬虫消耗掉大量的出入带宽和计算资源,最简单的办法就是限制单一IP地址的访问次数和速率。对于一些保存重要信息的网站,它的反爬技术会比较严密,它会严苛检查每一个IP的请求操作,然后对于可能是异常的请求,返回某一页面给对应请求或是提示需要登录信息等等甚至可能把相应的IP拉入黑名单[2]。每台计算机所分配到的公网IP是不能轻易大量规范的,当面临爬虫所用IP地址被禁止访问网站的内容时,不能随意和短时间内快速更换多个地址。因此,面对这种简单的防爬虫措施时,拥有一个可以随时调用且动态更新的可用代理池将会对数据获取起到中流砥柱的作用。
本项目通过自建IP代理池,动态维护代理池中的可用代理,通过大规模代理端口测试、多方代理池网站爬取获取可用代理,并且设计一套分数计算系统对可用代理进行评价,提高优质可用代理的优先级。本系统基于Flask框架提供API接口,可直接通过HTTP的GET请求获取JSON数据格式的可用代理列表,提高数据获取效率。
国内外研究现状
平安科技(深圳)有限公司的发明专利“网络爬虫方法、终端及存储介质”[3],介绍了一种网络爬虫方法,能一定程度上解决同一代理IP在长时间、多次快速、大量爬取数据的过程中的IP受限问题,但其对于IP的筛选仅仅是通过黑白名单的方法,不能对于短暂无法使用的代理“宽容”对待,即因网络等无法预料的原因就断定其无法再继续使用,也不能根据优先级选择可用的代理。
携程计算机技术(上海)有限公司的发明专利“一种动态IP代理池及其搭建及管理方法”[4],通过中央服务器维护代理,客户端发送心跳请求的方式获取可用的代理,但这种方法需要服务端与客户端的交互,造成了使用过程中的不方便。
GitHub中Nyloner的ProxyPool项目[5]通过对66ip、xicidaili这些发布一些可用代理网站进行爬取获取数据,来维护自建的代理池,但这些网站上面的代理质量参差不齐,无法对质量进行筛选和评价,带来实际使用代理时不可用的问题。
发展动态
高可用、高效率的代理池需要具备以下条件:代理列表动态维护;设立评分系统,延迟小、带宽大的代理应具有高优先级别;不可用的代理有暂时故障的可能,对其减分但不移除,后续应多次测试;不止依赖于一些网站的发布,系统应自有健全的可用代理扫描模块;系统对于外部有简单易用的API可供调用,并对可以请求进行甄别和限制。
二、项目研究内容、研究目标、以及解决的问题
研究内容
网络爬虫在数据获取方面具有极大的需要和作用,但爬虫会面临因使用单一IP请求频率过高而被网站限制的问题,因此需要维护一个可用的代理池,当IP被禁止访问时刻快速高效地切换代理继续进行爬虫工作。代理池应该拓宽获取待检测代理的范围,不能仅依靠已有的少量代理网站发布的数据;应该有合理的管理机制,不能只是简单地使用黑白名单;应该易于使用者调用,摆脱使用限制带来的困扰。
研究目标
对于网络爬虫对于大量可用代理的需求,针对现在已有的代理池项目存在获取代理的方式不稳定、管理代理的机制简陋、外部调用复杂等问题,本项目基于Flask框架,设计有评价机制、代理扫描机制、动态维护机制的动态代理池系统。
要解决的问题
- 拓宽代理检测的范围,有系统自有的获取方式,而不仅依赖已在一些网站上发布的低质量代理。
- 有合理的代理管理机制,对代理设立评价分数或优先级,对不可用的代理采取“宽容”政策,多次检验可用性。
- 用户调用方式应尽可能简单,数据获取方法应高效。 |
三、设计思路与实现方法
设计思路
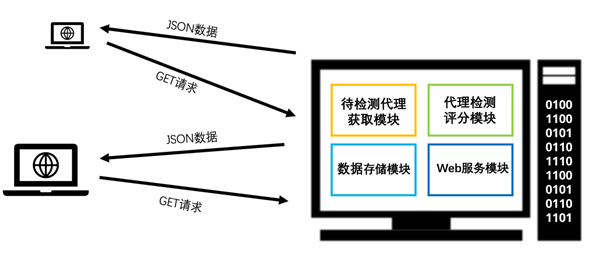
系统采取Flask框架,使用Redis数据库存储信息和实现数据持久化,各功能以插件的形式在系统中运行,提高系统整体协同性。主要功能模块如下
- 待检测代理获取模块
- 代理检测、评分模块
- 数据存储模块
- Web服务模块
系统框图
实现方法
待检测代理获取模块
本系统中待检测代理的获取方式有两种
-
全网段扫描常用代理端口是否可用,针对HTTP代理常用端口有8080、8888、9999等,HTTPS代理常用端口有9999等,SOCKS5代理常用端口有1080等,全网段扫描虽然耗费时间多、耗费资源大,但扫描出可用的数量多,是本系统采集待检测代理的主要方式。
-
爬取西刺代理、89免费代理等网站发布的代理数据,非主要获取途径。
代理检测
通过实际使用代理对百度首页的一张图片发送HTTP的HEAD请求,请求成功则证明代理可以使用,请求使用多线程,且记录每次请求的时间延迟。
评分
代理检测模块会在检测的同时,根据代理是否可用、延迟时间长短、最近被分享次数计算此代理对应的分数,分数高的则优先级高,即下次用户请求代理列表时优先级高的代理会排在较前。代理减分并不会立刻被放入不可用列表,当分数降低至某一值以下时才会从可用名单中去除,等待以后的多次检测。
数据存储模块
数据存储选择NoSQL数据库Redis,使用Redis中的有序集合方式存储,这样便于根据分数的排名以及调用。存放于内存中的Redis数据在数据读取和写入方面对比于硬盘读写有速度和效率上的优势,并且设置Redis数据在一定时间间隔后向硬盘中写入数据,保证即使断电也能数据持久化。
Web服务模块
搭建基于Flask框架的API,用户可通过GET请求获得指定数量可用代理JSON列表,API还提供以下功能
-
查询可用IP数量
-
通过身份认证后,可通过HTTP的DELETE请求删除某一特定代理。
四、开发与运行环境
运行环境
-
Python3
-
Ubuntu 18.04
-
Redis
所用模块
-
requests
-
flask
-
redis
-
pycurl
开发环境
Pycharm
五、软件截图
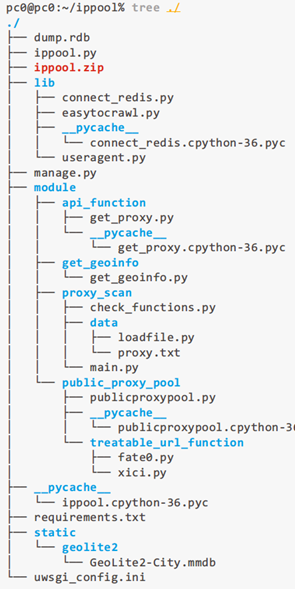
系统目录树
主要代码部分
ippool.py
|
|
get_proxy.py
|
|
proxy_scan/main.py
|
|
connect_redis.py
|
|
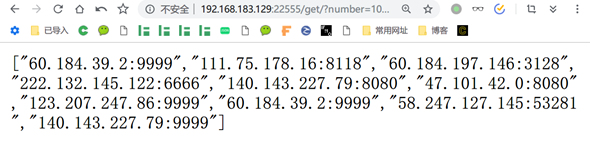
试验最终效果图
六、总结及展望
本系统通过完成待检测代理获取,代理检测、评分,数据存储,Web服务等模块,实现了高可用动态代理池功能,对于传统仅依赖黑白名单、依赖公开代理网站数据、查询存储速度慢、调用不方便等问题,提出了新的动态管理和提供Web服务理念,极大地解决了现存的问题。 代理池的搭建完成不是本项目的最终理念,维护一个动态高可用的代理池,并且形成简单易用和谐的氛围以及管理员和爬虫之间相互尊重的关系,才是互联网中开源精神的延伸和发展。